MAUVE: Measuring the Gap Between Neural Text and Human Text#
This is a library built on PyTorch and HuggingFace Transformers to measure the gap between neural text and human text with the MAUVE measure, introduced in this NeurIPS 2021 paper (Outstanding Paper Award) and a deeper dive in this JMLR 2023 paper.
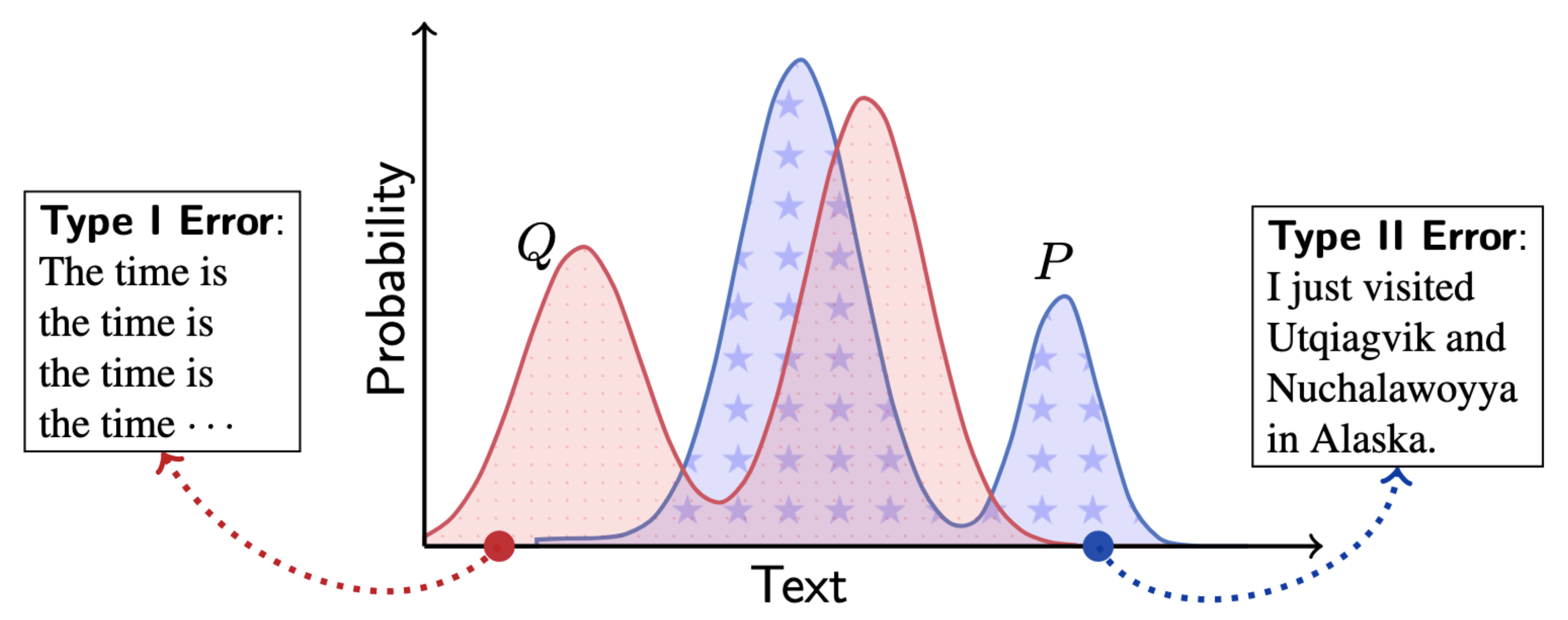
MAUVE is obtained by computing Kullback–Leibler (KL) divergences between the two distributions in a quantized embedding space of a foundation model.
In the text setting, it is natural to use embeddings from a pretrained large language model. It can quantify differences in the quality of generated text based on the size of the model, the decoding algorithm, and the length of the generated text. MAUVE was found to correlate the strongest with human evaluations over baseline metrics for open-ended text generation.
MAUVE can work with other modalities such as images, speech, music, or video, as long as domain-appropriate embeddings are obtained. Our API supports directly passing in such embeddings.
MAUVE is now also available via HuggingFace Evaluate.
The main features are:
MAUVE with k-means quantization
Adaptive selection of k-means hyperparameters
Compute MAUVE with text already encoded or use HuggingFace Transformers + PyTorch to compute encodings
Implementation of the Frontier Intergal, another divergence measure proposed in this NeurIPS 2021 paper.
Implementation of Krichevsky-Trofimov smoothing for smoothed divergence estimators (mauve_star and frontier_integral_star), as proposed in our JMLR 2023 paper.
Table of Contents#
Installation#
Once you have PyTorch >=1.7, you can grab MAUVE from pip:
$ pip install mauve-text
Alternatively, if you would like to edit the package, run
$ git clone git@github.com:krishnap25/mauve.git
$ cd mauve
$ pip install -e .
The installation command above installs the main requirements, which are numpy, scikit-learn, faiss and tqdm.
In addition, if you wish to use featurization within MAUVE, you need to manually install:
torch>=1.1.0: See Instructionstransformers>=3.2.0: Simply runpip install transformersafter PyTorch has been installed (Detailed Instructions here)
Quick Start#
Let p_text and q_text each be a list of strings, where each string is a complete generation (including context). For best practice, MAUVE needs at least a few thousand generations each for p_text and q_text (the paper uses 5000 each). For our demo, we use 100 generations each for fast running time.
To demonstrate the functionalities of this package on some real data, this repository provides some functionalities to download and use sample data in the ./examples folder of the MAUVE github repository:
$ git clone git@github.com:krishnap25/mauve.git
$ cd mauve
$ python examples/download_gpt2_dataset.py
The data is downloaded into the ./data folder. We can load the data (100 samples out of the available 5000) in Python as
>>> from examples import load_gpt2_dataset
>>> p_text = load_gpt2_dataset('data/amazon.valid.jsonl', num_examples=100) # human
>>> q_text = load_gpt2_dataset('data/amazon-xl-1542M.valid.jsonl', num_examples=100) # machine
We can now compute MAUVE as follows (note that this requires installation of PyTorch and HuggingFace Transformers, see the section on Installation)
>>> import mauve
>>> # call mauve.compute_mauve using raw text on GPU 0; each generation is truncated to 256 tokens
>>> out = mauve.compute_mauve(p_text=p_text, q_text=q_text, device_id=0, max_text_length=256, verbose=False)
>>> print(out.mauve) # prints 0.9917
This first downloads GPT-2 large tokenizer and pre-trained model (if you do not have them downloaded already). Even if you have the model offline, it takes it up to 30 seconds to load the model the first time. out now contains the fields:
out.mauve: MAUVE score, a number between 0 and 1 (higher values indicate that Q is closer to P)out.frontier_integral: a scalar divergence measure between P and Q, proposed in this paper (lower values indicate that Q is closer to P)out.mauve_starandout.mauve_frontier_integral_star: The corresponding versions with Krichevksy-Trofimov smoothing, as proposed in this JMLR 2023 paperout.divergence_curve: anumpy.ndarrayof shape (m, 2); plot it with matplotlib to view the divergence curveout.p_hist: a discrete distribution, which is a quantized version of the text distribution p_textout.q_hist: same as above, but with q_text
Functionality#
We now describe other ways of using MAUVE.
For each text (in both p_text and q_text), MAUVE internally uses the terimal hidden state from GPT-2 large as a feature representation. This feature encoding process can be rather slow (~10 mins for 5000 generations at a max length of 1024 on a GPU; but the implementation can be made more efficient, see Contributing). Alternatively, this package allows you to use cached hidden states directly (this does not require PyTorch and HuggingFace Transformers to be installed):
>>> # call mauve.compute_mauve using features obtained directly
>>> # p_feats and q_feats are `np.ndarray`s of shape (n, dim)
>>> # we use a synthetic example here
>>> import numpy as np
>>> p_feats = np.random.randn(100, 1024) # feature dimension = 1024
>>> q_feats = np.random.randn(100, 1024)
>>> out = mauve.compute_mauve(p_features=p_feats, q_features=q_feats)
The above functionality is helpful when using MAUVE with other modalities, as long as domain-appropriate features are obtained.
You can also compute MAUVE using the tokenized (BPE) representation using the GPT-2 vocabulary (e.g., obtained from using an explicit call to transformers.GPT2Tokenizer).
>>> # call mauve.compute_mauve using tokens on GPU 1
>>> # p_toks, q_toks are each a list of LongTensors of shape [1, length]
>>> # we use synthetic examples here
>>> import torch
>>> p_toks = [torch.LongTensor(np.random.choice(50257, size=(1, 32), replace=True)) for _ in range(100)]
>>> q_toks = [torch.LongTensor(np.random.choice(50257, size=(1, 32), replace=True)) for _ in range(100)]
>>> out = mauve.compute_mauve(p_tokens=p_toks, q_tokens=q_toks, device_id=1, max_text_length=1024)
To view the progress messages, pass in the argument verbose=True to mauve.compute_mauve. You can also use different forms as inputs for p and q, e.g., p via p_text and q via q_features.
Please see the detailed API here.
Best Practices for MAUVE#
MAUVE is quite different from most metrics in common use, so here are a few guidelines on proper usage of MAUVE:
Use for relative comparisons rather than absolute evaluation:
We find that MAUVE is best suited for relative comparisons while the absolute MAUVE score is less meaningful.
For instance, if we wish to find which of model1 and model2 are better at generating the human distribution, we can compare MAUVE(text_model1, text_human) and MAUVE(text_model2, text_human).
The absolute number MAUVE(text_model1, text_human) can vary based on the hyperparameters selected, but the relative trends remain the same.
One must ensure that the hyperparameters are exactly the same for the MAUVE scores under comparison.
Some hyperparameters are described below.
Number of generations: MAUVE computes the similarity between two distributions. Therefore, each distribution must contain at least a few thousand samples (we use 5000 each). MAUVE with a smaller number of samples is biased towards optimism (that is, MAUVE typically goes down as the number of samples increase) and exhibits a larger standard deviation between runs.
Number of clusters (discretization/quantization size): We take num_buckets to be 0.1 * the number of samples.
The performance of MAUVE is quite robust to this, provided the number of generations is not too small.
See the paper for details.
MAUVE is too large or too small:
The parameter
mauve_scaling_parametercontrols the absolute value of the MAUVE score, without changing the relative ordering between various methods. The main purpose of this parameter is to help with interpretability.If you find that all your methods get a very high MAUVE score (e.g., 0.995, 0.994), try increasing the value of
mauve_scaling_factor. (note: this also increases the per-run standard deviation of MAUVE).If you find that all your methods get a very low MAUVE score (e.g. < 0.4), then try decreasing the value of
mauve_scaling_factor.
MAUVE takes too long to run:
In our experiments (5000-10000 samples and
num_bucketsaround 500-1000), MAUVE runs in a few minutes, provided the feature encoding has been performed in advance.The feature encoding is the slowest part. Use a batch size as large as allowed for your GPU memory. For instance, with GPT-2 large as a featurizing model, a batch size of 8 works on a GPU with 12GB memory, resulting in a near 8x speedup.
To reduce the post-featurization runtime, you can also try reducing the number of clusters using the argument
num_buckets. The clustering algorithm's run time scales as the square of the number of clusters. Once the number of clusters exceeds 500, the clustering really starts to slow down. In this case, it could be helpful to set the number of clusters to 500 by overriding the default (which isnum_data_points / 10, so use this when the number of samples for each of p and q is over 5000).In this case, try reducing the clustering hyperparameters: set
kmeans_num_redoto 1, and if this does not help,kmeans_max_iterto 100. This enables the clustering to run faster at the cost of returning a worse clustering.
Contributing#
If you find any bugs, please raise an issue on GitHub. If you would like to contribute, please submit a pull request. We encourage and highly value community contributions.
Some features which would be good to have are:
feature encoding in HuggingFace Transformers with a TensorFlow backend.
Cite#
If you find this package useful, or you use it in your research, please cite:
@article{pillutla-etal:mauve:jmlr2023,
title={{MAUVE Scores for Generative Models: Theory and Practice}},
author={Pillutla, Krishna and Liu, Lang and Thickstun, John and Welleck, Sean and Swayamdipta, Swabha and Zellers, Rowan and Oh, Sewoong and Choi, Yejin and Harchaoui, Zaid},
journal={JMLR},
year={2023}
}
@inproceedings{pillutla-etal:mauve:neurips2021,
title={MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers},
author={Pillutla, Krishna and Swayamdipta, Swabha and Zellers, Rowan and Thickstun, John and Welleck, Sean and Choi, Yejin and Harchaoui, Zaid},
booktitle = {NeurIPS},
year = {2021}
}
@inproceedings{liu-etal:mauve-theory:neurips2021,
title={{Divergence Frontiers for Generative Models: Sample Complexity, Quantization Effects, and Frontier Integrals}},
author={Liu, Lang and Pillutla, Krishna and Welleck, Sean and Oh, Sewoong and Choi, Yejin and Harchaoui, Zaid},
booktitle={NeurIPS},
year={2021}
}
Acknowledgments#
This work was supported by NSF DMS-2134012, NSF CCF-2019844, NSF DMS-2023166, the DARPA MCS program through NIWC Pacific (N66001-19-2-4031), the CIFAR "Learning in Machines & Brains" program, a Qualcomm Innovation Fellowship, and faculty research awards.